在 SQL 中,多表查询是指同时涉及两个或多个表的查询操作。基于表之间的关系和联接方式的不同,可以归纳出以下几种常见的多表查询类型:
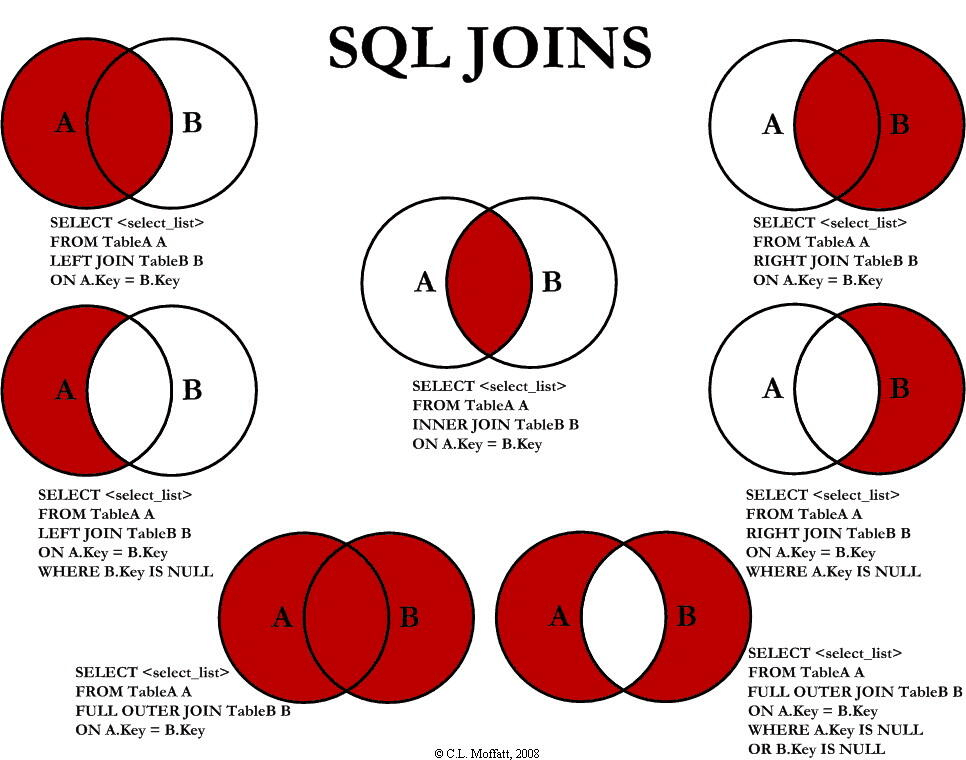
内连接(Inner Join): 内连接使用 INNER JOIN 或 JOIN 关键字来联接两个或多个表,并返回满足关联条件的匹配行。
左连接(Left Join): 左连接使用 LEFT JOIN 或 LEFT OUTER JOIN 关键字来联接两个表,并返回左表的所有行以及满足关联条件的匹配行。如果右表中没有匹配的行,对应的列将包含 NULL 值。
右连接(Right Join): 右连接使用 RIGHT JOIN 或 RIGHT OUTER JOIN 关键字来联接两个表,并返回右表的所有行以及满足关联条件的匹配行。如果左表中没有匹配的行,对应的列将包含 NULL 值。
全连接(Full Join): 全连接使用 FULL JOIN 或 FULL OUTER JOIN 关键字来联接两个表,并返回左表和右表的所有行。如果某个表中没有匹配的行,对应的列将包含 NULL 值。
交叉连接(Cross Join): 交叉连接使用 CROSS JOIN 关键字来联接两个表,返回两个表的笛卡尔积,即左表中的每一行与右表中的每一行的组合。
这些多表查询类型提供了不同的联接方式,用于处理涉及多个表的复杂查询需求。可以根据具体的数据关系和查询目的来选择合适的多表查询方式。
需要注意的是,不是所有的数据库系统都支持所有类型的JOIN操作。例如,MySQL支持所有这些JOIN操作,但SQLite就只支持内连接和左连接。因此左连接和右连接在功能上是等价的,但在实际使用中,左连接在各种数据库系统中的支持更好。
内连接
内连接(INNER JOIN):只返回两个表中匹配的行。如果某行在其中一个表中没有匹配,那么结果集中将不会显示这一行。例如:
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID;
上述查询会选择Orders表和Customers表中CustomerID相同的所有订单和客户名。
左连接
左连接(LEFT JOIN):返回左表中的所有行,即使在右表中没有匹配的行。如果没有匹配,结果集中右表的部分将为NULL。例如:
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
LEFT JOIN Customers ON Orders.CustomerID = Customers.CustomerID;
这个查询会返回Orders表中的所有订单,并包含与这些订单匹配的Customers表中的客户名。如果某个订单没有匹配的客户,那么CustomerName将为NULL。
右连接
右连接(RIGHT JOIN):返回右表中的所有行,即使在左表中没有匹配的行。如果没有匹配,结果集中左表的部分将为NULL。例如:
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
RIGHT JOIN Customers ON Orders.CustomerID = Customers.CustomerID;
这个查询会返回Customers表中的所有客户,并包含与这些客户匹配的Orders表中的订单。如果某个客户没有匹配的订单,那么OrderID将为NULL。
全连接
全连接(FULL JOIN):返回两个表中所有的行。如果没有匹配,结果集中将会使用NULL来填充。例如:
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
FULL JOIN Customers ON Orders.CustomerID = Customers.CustomerID;
这个查询会返回Orders表和Customers表中的所有订单和客户。如果某个订单没有匹配的客户,那么CustomerName将为NULL。如果某个客户没有匹配的订单,那么OrderID将为NULL。
笛卡尔积
在SQL中,笛卡尔积是两个表中所有行的所有可能组合。如果你想要得到笛卡尔积,你可以直接列出两个表,而不需要指定任何连接条件。
SELECT colors.color, sizes.size
FROM colors, sizes;
在实际应用中,我们通常会避免笛卡尔积,因为它往往会导致结果集过大,包含大量的无关数据。一般情况下,我们会指定一个连接条件(使用ON关键字),以便只获取需要的数据。
连接条件
在SQL中on后面表示的是连接条件,例如:
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
FULL JOIN Customers ON Orders.CustomerID = Customers.CustomerID AND month(date)=8;
上面这段SQL表示只有两个表的ID相等,并且连接表中date字段为8月的数据才允许被连接。