##PyInstaller打包不同的Python版本程序。
因为Python 3.9以后的版本不再支持Windows 7系统,当我们打包的.exe程序需要在Windows 7系统上运行时,必须使用较低版本的Python解释器,如Python 3.8。
我一开始使用Python 3.10打包程序,当生成的.exe程序到Windows7系统上运行时候会报错误:
无法启动此程序,因为计算机中丢失api-ms-win-core-path-l1-1-0.dll。
因此,我需要用Python 3.8来打包我程序。但我们在打包时使用的命令:PyInstaller -F。是使用当前系统环境变量中默认的Python解释器版本。
也就是说,当系统环境变量中默认为Python 3.10(已安装了PyInstaller包),那PyInstaller命令打包的程序会默认使用Python 3.10的环境。
我并没有更好的办法,只能新下载一个Python 3.8的解释器,并且将环境变量也设置成Python 3.8。还需要在Python 3.8中安装PyInstaller包。否则PyInstaller -F命令可能会无效或继续使用Python 3.10的解释器。
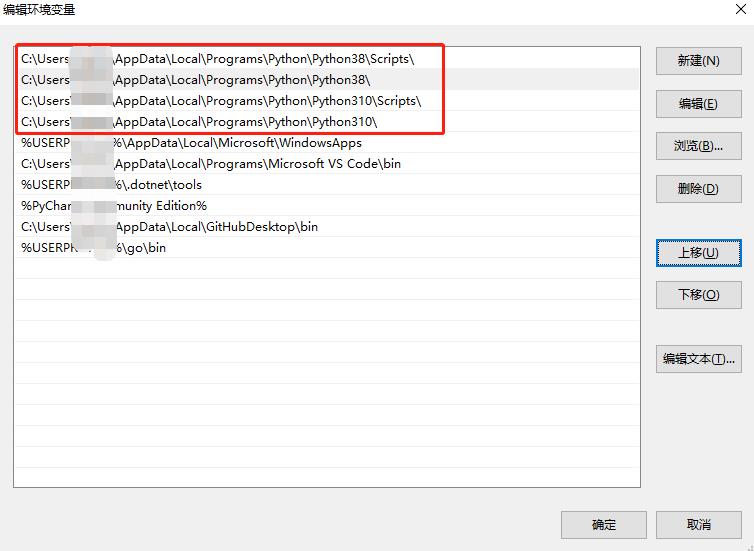
环境变量中Python 3.8的路径在Python 3.10上方。在终端中执行的Python命令会优先使用Python 3.8的解释器。如果找不到才会去找Python 3.10的解释器。
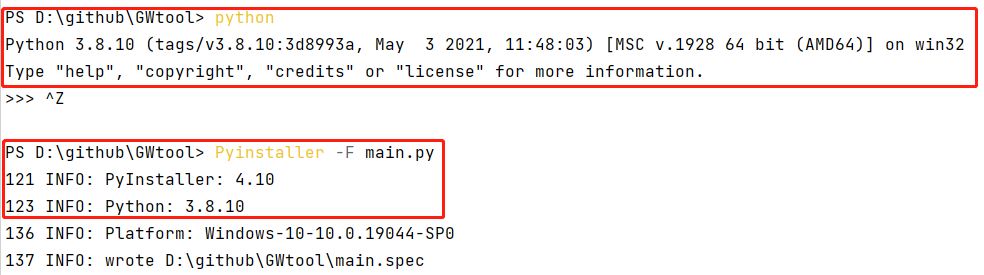
在系统变量中我使用了Python 3.8的版本,并且安装了PyInstaller包。接下来使用PyInstaller的打包命令:PyInstaller -F main.py。打包后的.exe程序使用的就是系统变量中的Python 3.8版本解释器。
总结:如果你希望你打包的程序使用某个版本的Python解释器,例如Python 3.8版本。那你需要做以下几件事:
- 1、下载你需要的版本的Python解释器——下载Python 3.8版本的解释器。
- 2、将系统变量配置成你需要的Python解释器——在命令行(终端)中输入Python后显示的是Python 3.8版本。
- 3、安装PyInstaller包——PyInstaller必须在Python 3.8的环境中。
- 4、在你的程序中使用PyInstaller的打包命令——在打包时候显示Python: 3.8。
在打包时显示使用的Python版本就是你程序所使用的Python解释器。
这里我多说两句,通常我们的开发环境和我们使用的操作系统环境是不一样的。我开发的程序使用的是Python 3.10。因为我的IDE指向的是某个固定的解释器,也就是Python 3.10。但我的操作系统环境变量是指向另一个解释器。而终端是依附操作系统的,使用终端打包就容易出现,打包环境和开发环境不一致的情况。