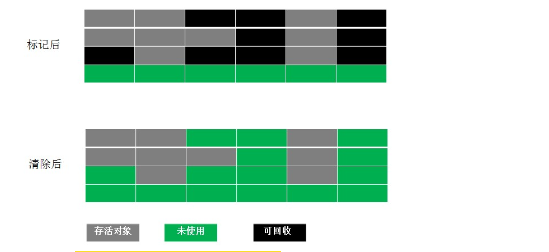
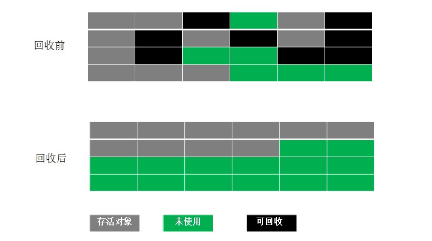
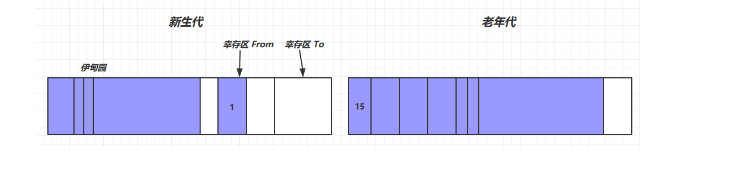
Java的基本数据类型。
基本数据类型是四类八种:
- 字符类型:char
- 布尔类型:boolean
- 数值类型:byte(1字节)、short(2字节)、int(4字节)、long(8字节)
- 浮点型:float、double。
扩展——引用数据类型非常多:数组、类、接口、枚举等。
引用数据类型也按照GC来划分:强引用、弱引用、软引用、虚引用。
数据流的种类。
按照流的方向分为:输入流、输出流
按照实现功能分为:节点流、处理流
按照数据处理的单位分为:字节流、字符流
说几个你知道的异常类
空指针异常、MMO异常、下标越界异常、字符串与数字的转换异常、文件未找到异常等。
扩展——异常的关系,分为error和exception。而exception还细分为runtimeExcepton和其它。
runtimeException叫做运行异常,其它的叫编译异常。编译异常需要在源代码中检查,因此也叫做受检异常。runtimeException也叫做非受检异常。error也是为非受检异常。
知道hashmap和hashtable么,这两个有什么区别?
hashmap是线程不安全、hashtable是线程安全的。
hashtable是早期的Java集合,实现的是其他接口,并继承其他的类。但hashmap是实现了Map接口。
hashtable不允许有Null键或者Null值,而hashmap允许有一个Null键或多个Null值。
还有一些迭代器的区别和性能的区别。因为线程安全,hashtable在竞争条件下的性能会受到影响。
还有很多其他的。
说说set和list的异同点。
Set和List是Java集合框架中两种常见的接口,它们在数据存储和访问方式上有一些异同点。
相同点:
- 都是集合接口:Set和List都是Java集合框架中的接口,用于表示一组对象的集合。
- 支持存储多个元素:Set和List都可以存储多个元素,可以根据需要进行动态添加或删除元素。
不同点:
- 元素的顺序:List中的元素是有序的,每个元素都有一个对应的索引值,可以根据索引值访问和操作元素。而Set中的元素是无序的,不保证元素的存储顺序。
- 元素的唯一性:List允许存储重复的元素,同一个元素可以多次出现在List中。而Set中不允许存储重复的元素,每个元素在Set中只能出现一次。
- 实现类:Java提供了多个Set和List的实现类。常见的Set实现类有HashSet、TreeSet和LinkedHashSet,而常见的List实现类有ArrayList、LinkedList和Vector。
- 检索和遍历:由于List中的元素是有序的且有索引,可以通过索引值直接访问和操作元素,适用于根据位置进行快速检索。而Set中的元素是无序的,不能通过索引值访问元素,需要使用迭代器或者增强型for循环进行遍历。
- 性能:由于List中的元素是有序的且有索引,对于索引访问的操作性能较好。而Set需要维护元素的唯一性,可能需要进行更多的判断和比较操作,性能上相对较低。
综上所述,Set和List在元素的顺序、唯一性、实现类、检索和遍历方式以及性能等方面存在一些异同点。根据具体的需求和场景,选择合适的集合类型可以提高代码的效率和可读性。
spring的两大特点。
DI和AOP、依赖注入和面向切面编程。
说说你知道的几个数据库引擎
在MySQL workbench中有九种。
- InnoDB
- MyISAM
- MEMORY
- archive
- 。。。
MySQL支持几种存储引擎
redis的五种数据类型。
- String
- List
- Hash
- Set
- Zset
几种返回的响应状态码。
五大类。
- 信息响应 (100 – 199)
- 成功响应 (200 – 299)
- 重定向消息 (300 – 399)
- 客户端错误响应 (400 – 499)
- 服务端错误响应 (500 – 599)
几种请求类型。
一共九种。
HTTP1.0 定义了三种请求方法: GET,POST 和 HEAD 方法。
HTTP1.1 新增了六种请求方法:OPTIONS、PUT、PATCH、DELETE、TRACE 和 CONNECT 方法。
有什么鉴权模块。
JSON Web Token(JWT)
乐观锁和悲观锁。
乐观锁(Optimistic Locking)和悲观锁(Pessimistic Locking)是在并发控制中使用的两种不同的策略,用于管理多个线程或进程同时访问和修改共享数据的情况。
- 乐观锁: 乐观锁的基本思想是,假设并发访问的线程之间不会产生冲突,因此不会阻塞任何线程。线程在读取数据时并不立即加锁,而是在更新数据时检查是否有其他线程已经修改了相同的数据。如果没有冲突,线程可以继续执行更新操作。如果发现冲突,乐观锁机制会触发回滚或重试操作。
乐观锁的实现通常通过版本号或时间戳来实现。在每次更新操作时,会比较当前数据的版本号或时间戳与之前读取时的值是否一致,如果一致则可以进行更新,否则认为发生了冲突。
- 悲观锁: 悲观锁的基本思想是,假设并发访问的线程之间会产生冲突,因此对数据进行加锁,以防止其他线程对数据的修改。线程在读取和更新数据之前,会先获取锁,确保其他线程无法同时访问和修改该数据。只有当前线程释放了锁之后,其他线程才能获得锁并进行操作。
悲观锁的实现通常依靠数据库的锁机制或并发控制工具来实现,例如使用数据库中的行级锁或使用 synchronized 关键字来保证数据的独占访问。
选择乐观锁还是悲观锁取决于具体的应用场景和需求。乐观锁适用于读操作较多、冲突较少的情况,可以提高并发性能。悲观锁适用于写操作较多、冲突较多的情况,可以确保数据的一致性和完整性。
用什么自动化部署方式。CICD
Jinkins、Docker、GitLab CI/DI、云服务提供商的自动化部署。提交代码以后可以直接部署。
如何解决脏数据的问题。
脏数据(Dirty Data)是指在数据库或数据集中存在错误、不一致或无效的数据。这些数据可能是由于人为错误、系统故障、数据传输问题或其他原因导致的。
脏数据有:无效数据、冗余数据、不一致数据、缺失数据。
内存数据跟磁盘数据内容不一致称为脏数据。
例如设置了缓存失效时间(比如1小时),那么在这一小时内,如果有人更新了DB的数据,只要缓存不失效,Redis就不会主动读取DB并更新数据,那么用户看到的其实都是旧的数据,与DB不一致,此谓缓存脏读。
找到更新数据的入口,每次更新DB都同步或异步更新缓存。
我记得好像有不同的更新方式。
如何处理脏数据?
数据清洗,异常值检测、数据验证和修复,数据合并和去重。
- 数据清洗:通过数据清洗过程,识别和纠正脏数据。这包括删除重复数据、修复格式错误、填补缺失值、校验数据一致性等操作。
- 异常值检测:检测和处理异常值,这些值可能是数据采集或输入过程中的错误或异常情况。可以使用统计方法、数据规则或机器学习算法来识别和处理异常值。
- 数据验证和修复:实施数据验证规则和约束,确保数据的准确性和完整性。定期进行数据验证,并根据需要修复或纠正错误的数据。
- 数据合并和去重:如果存在多个数据源或数据副本,进行数据合并和去重操作,以确保数据的一致性和唯一性。
如何避免脏数据?
数据采集和输入验证、数据库约束和规则、数据访问控制、数据培训和文档化、数据监控和审核。
- 数据采集和输入验证:在数据采集和输入过程中进行验证,包括验证数据格式、范围、类型和约束等。使用输入验证、正则表达式、预定义规则等来确保有效数据的录入。
- 数据库约束和规则:定义和应用数据库约束和规则,包括主键、外键、唯一性约束、检查约束等,以确保数据的完整性和一致性。
- 数据访问控制:实施适当的数据访问控制机制,限制对数据的访问和修改,防止非授权的数据修改或错误操作。
- 数据培训和文档化:提供数据培训和文档,确保数据录入和处理人员了解数据的规则、格式和要求,并正确操作数据。
- 数据监控和审核:定期监控和审查数据,发现和解决潜在的脏数据问题。使用数据质量工具或建立监控系统来识别异常和错误数据。
可以最大程度地减少脏数据的发生,并提高数据的准确性、一致性和可靠性。
说说spring对你来说厉害的地方。
轻量级和非侵入性:Spring 框架采用轻量级的设计原则,不需要强制性地继承或实现特定的类或接口。开发人员可以根据需要选择使用 Spring 提供的功能,而无需修改现有的应用程序架构。
容器管理:Spring 容器提供了对象的创建、配置和管理。通过配置文件或注解,开发人员可以声明和组织对象及其依赖关系,实现松耦合的组件化开发。
丰富的集成支持:Spring 提供了广泛的集成支持,可以轻松地集成和使用其他流行的框架和技术,如数据库访问、Web 开发、安全性、消息传递等。
开放源代码和活跃的社区支持:Spring 是一个开源框架,具有庞大和活跃的开发者社区。这意味着开发人员可以充分利用社区提供的资源、文档和支持来解决问题和获取帮助。
如何使用mybatis
如何优化(从数据库、缓存、多线程方向)
数据库连接的开销非常大、如何优化连接池。
操作数据库需要和数据库建立连接,拿到连接之后才能操作数据库,用完之后销毁。数据库连接的创建和销毁其实是比较耗时的,真正和业务相关的操作耗时是比较短的。每个数据库操作之前都需要创建连接,为了提升系统性能,后来出现了数据库连接池,系统启动的时候,先创建很多连接放在池子里面,使用的时候,直接从连接池中获取一个,使用完毕之后返回到池子里面,继续给其他需要者使用,这其中就省去创建连接的时间,从而提升了系统整体的性能。
如何解决负载均衡。
缓存?
cookie和localStorage和sessionStorage
这三个都是和客户端那边存储信息相关的。
- cookie,主要用来保存登录信息。
- localStroage,生命周期是永久的。
- sessionStroage,生命周期与浏览器相关。
- Cookie:
- Cookie 是由服务器发送给浏览器并存储在客户端的小型文本文件。它通常用于跟踪用户会话、实现用户认证、存储用户偏好等。
- Cookie 在每次HTTP请求中都会被发送到服务器,因此可用于在客户端和服务器之间共享数据。
- Cookie 可以设置过期时间,在过期之前会一直保留在客户端。可以设置持久性 Cookie,使其在浏览器关闭后仍然存在,或设置会话 Cookie,使其在用户会话结束时过期。
- localStorage:
- localStorage 是HTML5引入的持久性存储机制,允许在浏览器中存储键值对的数据。
- localStorage 存储的数据没有过期时间,除非主动清除或通过代码删除,否则会一直保留在客户端。
- localStorage 只能通过JavaScript访问,数据在同一域名下的页面间共享。
- sessionStorage:
- sessionStorage 也是HTML5引入的存储机制,类似于localStorage,但是数据在浏览器会话结束后会被清除。
- sessionStorage 适用于存储临时性的会话数据,它只在当前会话期间有效,当用户关闭浏览器选项卡或窗口时,数据会被删除。
总结:
- Cookie 是最早的用于在客户端存储数据的机制,适用于跟踪用户和存储简单的数据,但每次请求都会发送到服务器。
- localStorage 提供了持久性存储,适用于在同一域名下的页面间共享数据。
- sessionStorage 提供了临时性存储,数据在会话结束后被清除,适用于会话期间的数据共享。
跨域是什么,如何解决。
出现了以下情况中的任意一种,那么它就是跨域请求:
- 协议不同,如 http 和 https;
- 域名不同;
- 端口不同。
- JSONP(JSON with Padding)
- CORS(Cross-Origin Resource Sharing)
- 反向代理,反向代理是将客户端的请求转发到真正的服务端,从而解决跨域问题。
- WebSocket
在 Spring Boot 中跨域问题有很多种解决方案,比如以下 5 个:
- 使用 @CrossOrigin 注解实现跨域;
- 通过配置文件实现跨域;
- 通过 CorsFilter 对象实现跨域;
- 通过 Response 对象实现跨域;
- 通过实现 ResponseBodyAdvice 实现跨域。
当然如果你愿意的话,还可以使用过滤器来实现跨域,但它的实现和第 5 种实现类似
对不起,没面试成功是我还是太菜了。